

随着人工智能技术的快速发展,多模态理解已成为研究的前沿。日前,阿里云再度为全球开发者带来惊喜,推出并开源其先进的多模态视觉模型——Qwen-VL。但许多人可能仍然对“多模态”感到陌生,这次,我们为您详细解读。
通义千问的多模态是什么意思
Qwen-VL,作为一个前沿的视觉语言模型,支持多种语言,包括中英文。与传统的VL模型相比,Qwen-VL不仅能进行图文识别、描述、问答和对话,还新添了视觉定位以及图像中的文字理解等功能,表现得尤为出色。基于此,官方自信地表示其性能“远超同等规模的通用模型”。
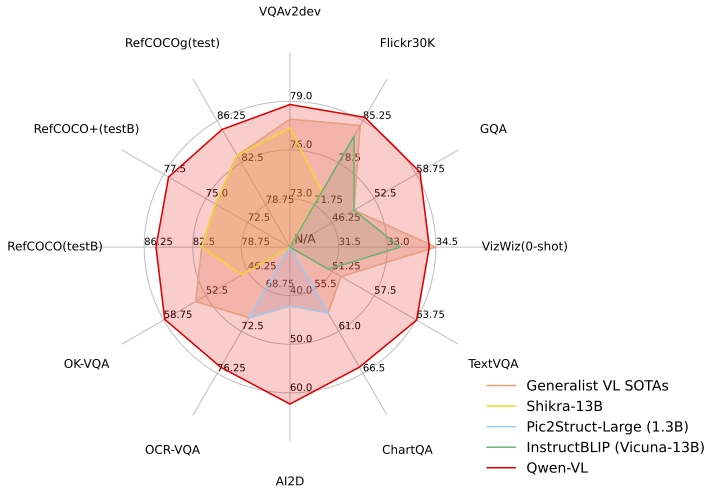
此模型在技术构建上非常精巧。它以阿里云之前开源的Qwen-7B作为基础,巧妙地融入了视觉编码器,从而支持视觉信号输入。值得一提的是,Qwen-VL能够处理高达448的图像输入分辨率,而市面上大多数LVLM模型仅支持224分辨率。
在Qwen-VL之上,阿里云进一步创新,结合对齐机制推出了基于LLM的视觉AI助手——Qwen-VL-Chat。这一新成员将助力开发者轻松构建出具有多模态能力的对话应用。
为了进一步证明其实力,通义千问团队设计了一套基于GPT-4打分机制的测试集——“试金石”。在该测试集上,Qwen-VL-Chat与其他模型进行了一番激烈的竞争,结果令人振奋:在中英文的对齐评测中,Qwen-VL-Chat均荣获了开源LVLM的最佳成绩。
阿里云此次开源的Qwen-VL无疑为多模态理解领域带来了新的活力。我们有理由相信,在不久的将来,这样的技术将为各行各业带来更多的可能性和创新机会。

















